data completeness
tags: data engineering
streaming data completeness with reference, 21 Jan 2021
What’s the problem of data completeness?
There are various definitions of data completeness. However, in this writing, data is considered complete when its actual count matches the desired count to be fit for use. The mismatch could happen due to missing or duplicate records. Note that the focus here is the missing of the whole record, not some fields of the record, e.g. NULL values.
How’s it viewed from data quality perspective?
According to [1], data quality comprises of multiple dimensions as shown in figure below. Four major dimensions are intrinsic, accessibility, contextual, and representational.
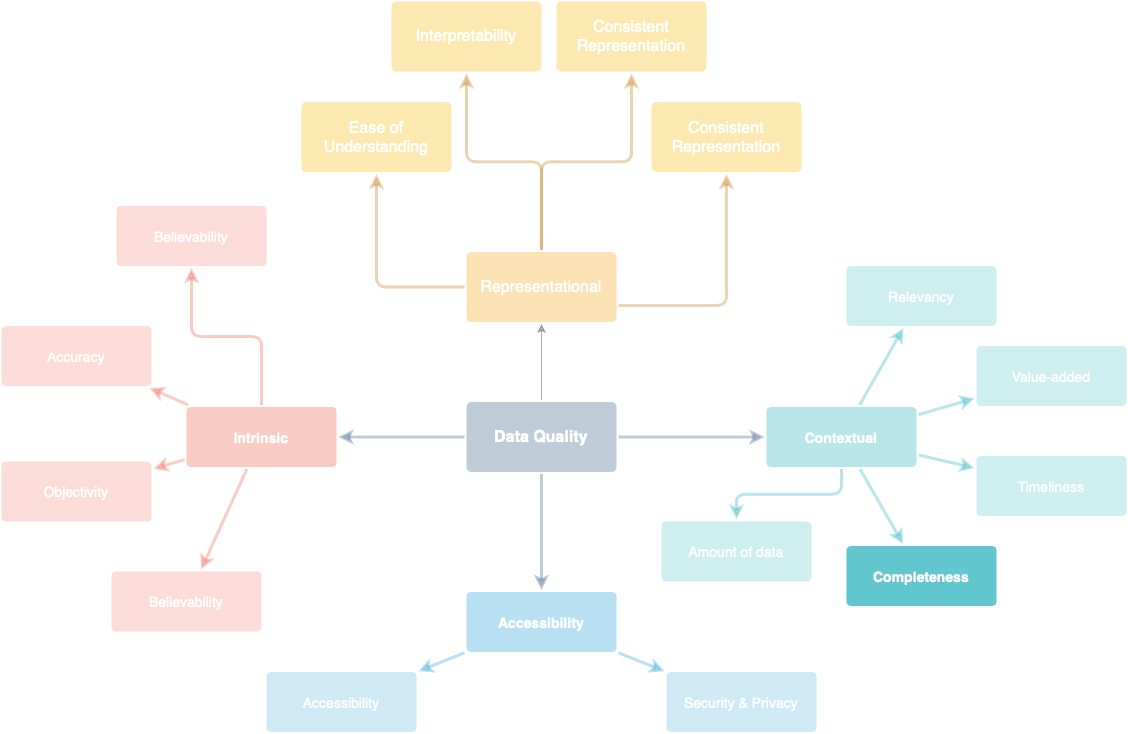
Data completeness is within the contextual category. This implies that the requirement for data completeness actually depends on the context: the task at hand. For example, when transactional data is used for accounting reconciliation purpose, it’s important to have near 100% completeness. On the other hand, when behavioural data is used for customer analysis, completeness of 90-95% might be useful. This is important to note when single data is used for multiple purposes.
What to do about it?
According to [2], data completeness problem could be viewed within 2 categories: with and without reference. Reference is where the data is derived from. The paper continues with the case without reference; however, that’s beyond the scope of this writing. In the presence of reference, we could use the reference as a basis for completeness evaluation. Figure below shows an example in which replica isn’t derived directly from reference but through production apps.
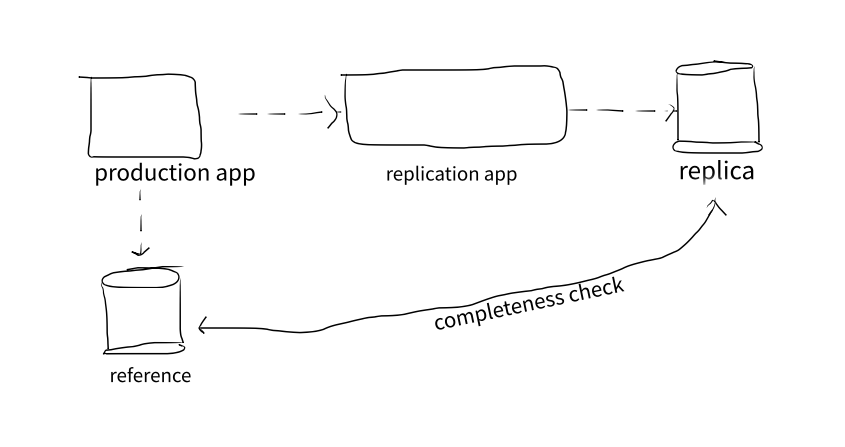
Due to the nature of distributed systems, there is no guarantee that the records will be fully replicated. Consistency isn’t natural especially in the absence of expensive distributed transaction. To add insults to injury, we don’t even have any upper bound of missing data. So, one day it could be 1% and the next day 50% with none is aware. And the good news is we might not need (near) 100% completeness in all use cases. Therefore, the purpose of this evaluation is simply to annotate the replication process with percentage of completeness. With that information in mind, we could put that information in context and decide whether the replica is fit for use or require re-replication.
Reference
- [1] Strong, D. et al. “Data quality in context.” Commun. ACM 40 (1997): 103-110.
- [2] Klein, A. et al. “Representing Data Quality for Streaming and Static Data.” 2007 IEEE 23rd International Conference on Data Engineering Workshop (2007): 3-10.